Além de paralelização nos vários threads/cores da sua CPU, você pode paralelizar na sua placa gráfica GPU (se ela for NVIDIA e tiver o protocolo CUDA). Isso é possível pela biblioteca Thrust da NVIDIA.

Figure 1: Código {Rcpp} rodando em paralelo na GPU
Biblioteca Thrust da NVIDIA
Thrust é uma biblioteca de algoritmos paralelos que se assemelha à biblioteca padrão C++ STL. Thrust usa a interface CUDA da NVIDIA. CUDA, sigla para Compute Unified Device Architecture, é uma extensão para a linguagem de programação C, a qual possibilita o uso de computação paralela. A ideia por trás disso tudo é que programadores possam usar os poderes da unidade de processamento gráfico (GPU) para realizar algumas operações mais rapidamente.
Para quase tudo da STL, é só você mudar alguns headers e o namespace de std:: para thrust::. Thrust fornece dois contêineres de vetor, thrust::host_vector e thrust::device_vector. Como os nomes sugerem, thrust::host_vector é armazenado na memória da CPU, enquanto thrust::device_vector vive na memória do dispositivo GPU. Os contêineres de vetor da Thrust são como std::vector no C++ STL. Como std::vector, thrust::host_vector e thrust::device_vector são recipientes genéricos (capazes de armazenar qualquer tipo de dados) que podem ser redimensionados dinamicamente.
Instalando e Habilitando o Thrust
O primeiro passo é instalar o Thrust. Ele vem automaticamente quando você instala o CUDA Toolkit da NVIDIA. Como vocês podem ver nesse Ubuntu eu tenho CUDA versão 11.0 (sendo que precisei instalar o g++-9 versão 9 que dá suporte ao nvcc da NVIDIA) e uma GeForce RTX 2060 com 6GB de RAM. Veja como instalar Thrust na documentação da NVIDIA-CUDA.
nvidia-smiMon Jan 11 17:02:04 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 2060 Off | 00000000:01:00.0 Off | N/A |
| N/A 43C P8 3W / N/A | 321MiB / 5934MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3430 G /usr/lib/xorg/Xorg 66MiB |
| 0 N/A N/A 3878 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 130028 C ...tudio-server/bin/rsession 239MiB |
+-----------------------------------------------------------------------------+O segundo passo é criar um plugin no {Rcpp}. Para isso, vamos ver o caminho do nvcc no meu sistema.
which nvcc/usr/bin/nvccCom esse caminho eu crio um plugin para {Rcpp} com a função registerPlugin(). Notem que estou usando o padrão C++17 (mais recente que g++-9 dá suporte).
library(Rcpp)
thrust = function() {
list(
env = list(
MAKEFLAGS = paste(
"CXX=/usr/bin/nvcc",
"CXXFLAGS=-x\\ cu\\ -g\\ -G\\ -O3 --std=c++17",
"CXXPICFLAGS=-Xcompiler\\ -fpic\\ -Xcudafe\\ --diag_suppress=code_is_unreachable",
"LDFLAGS="
),
PKG_CXXFLAGS = paste0("-I", here::here())
)
)
}
Rcpp::registerPlugin("thrust", thrust)
ls(envir=Rcpp:::.plugins)
[1] "cpp0x" "cpp11" "cpp14" "cpp17"
[5] "cpp1y" "cpp1z" "cpp2a" "cpp98"
[9] "openmp" "thrust" "unwindProtect"Terceiro passo é colocar em qualquer parte do código CUDA o seguinte texto indicando que {Rcpp} deve usar o plugin thrust.
// [[Rcpp::plugins(thrust)]]É isso! Um pouco mais difícil que os outros plugins que usamos até aqui porque tivemos que criá-lo do zero. Mas nada impossível.
Exemplo – Soma dos Quadrados
Vamos reutilizar o exemplo sum_of_squares do tutorial 2. Como incorporar C++ no R - {Rcpp}, agora comparando {RcppParallel} com a biblioteca Thrust da NVIDIA.
Soma dos quadrados é algo que ocorre bastante em computação científica, especialmente quando estamos falando de regressão, mínimos quadrados, ANOVA etc. Vamos paralelizar a implementação ingênua que fizemos no tutorial 2. Como incorporar C++ no R - {Rcpp} com dois loops for. Lembrando que esta implementação será uma função que aceita como parâmetro um vetor de números reais (C++ double / R numeric) e computa a soma de todos os elementos do vetor elevados ao quadrado.
Aqui vamos inserir um std::accumulate() do header <numeric>.
Soma dos Quadrados usando Thrust
Novamente vou incluir comentários para o entendimento do que estamos fazendo no {RcppParallel}.
library(RcppParallel)
setThreadOptions(parallel::detectCores())
print(parallel::detectCores())
[1] 12#include <Rcpp.h>
#include <RcppParallel.h>
#include <algorithm>
using namespace RcppParallel;
using namespace Rcpp;
// [[Rcpp::depends(RcppParallel)]]
// [[Rcpp::plugins("cpp11")]]
// [[Rcpp::plugins("cpp2a")]]
// Criando um objeto Worker chamado sum_of_squares
struct sum_of_squares : public Worker
{
// Variáveis Membro públicas
const RVector<double> input;
double value;
// Construtor padrão do Objeto Worker
sum_of_squares(const NumericVector input) : input(input), value(0) {}
// Construtor "divisor"
sum_of_squares(const sum_of_squares& sum, Split) : input(sum.input), value(0) {}
// Overload do operador () -- functor
void operator()(std::size_t begin, std::size_t end) {
value += std::accumulate(input.begin() + begin,
input.begin() + end,
0.0,
[] (auto i, auto j) {return i + (j * j);});
}
void join(const sum_of_squares& rhs) {
value += rhs.value;
}
};
// Função que chama o Objeto Worker sum_of_squares
// [[Rcpp::export]]
double parallel_sum_of_squares(NumericVector x) {
// variável local inicializada
sum_of_squares sum(x);
// Paralelização do Reduce
parallelReduce(0, x.length(), sum);
return sum.value;
}Soma dos Quadrados usando Thrust
No arquivo SS_Thrust.cpp usamos os headers <thrust> e também chamamos os objetos Thrust com o namespace thrust::. std::acummulate() vira thrust::transform_reduce().
writeLines(readLines("SS_Thrust.cpp"))
#include <Rcpp.h>
#include <thrust/device_vector.h>
#include <thrust/functional.h>
#include <thrust/transform_reduce.h>
// [[Rcpp::plugins(thrust)]]
// [[Rcpp::export]]
double thrust_sum_of_squares(Rcpp::NumericVector& v){
// cria um device_vector na GPU copiando todos os elementos do NumericVector v
thrust::device_vector<double> dv(v.cbegin(), v.cend());
double sum_of_squares = thrust::transform_reduce(dv.cbegin(),
dv.cend(),
thrust::square<double>(),
0L,
thrust::plus<double>());
return sum_of_squares;
}sourceCpp("SS_Thrust.cpp")
set.seed(123)
b1 <- bench::press(
n = 10^c(6:8),
{
v = rnorm(n)
bench::mark(
RcppParallel = parallel_sum_of_squares(v),
Thrust = thrust_sum_of_squares(v),
check = FALSE,
relative = TRUE
)
})
b1
# A tibble: 6 x 7
expression n min median `itr/sec` mem_alloc `gc/sec`
<bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 RcppParallel 1000000 1 1 62.5 1 NaN
2 Thrust 1000000 58.9 52.9 1 1 NaN
3 RcppParallel 10000000 1 1 25.7 1 NaN
4 Thrust 10000000 25.5 25.9 1 1 NaN
5 RcppParallel 100000000 1 1 23.8 1 NaN
6 Thrust 100000000 24.0 23.9 1 1 NaN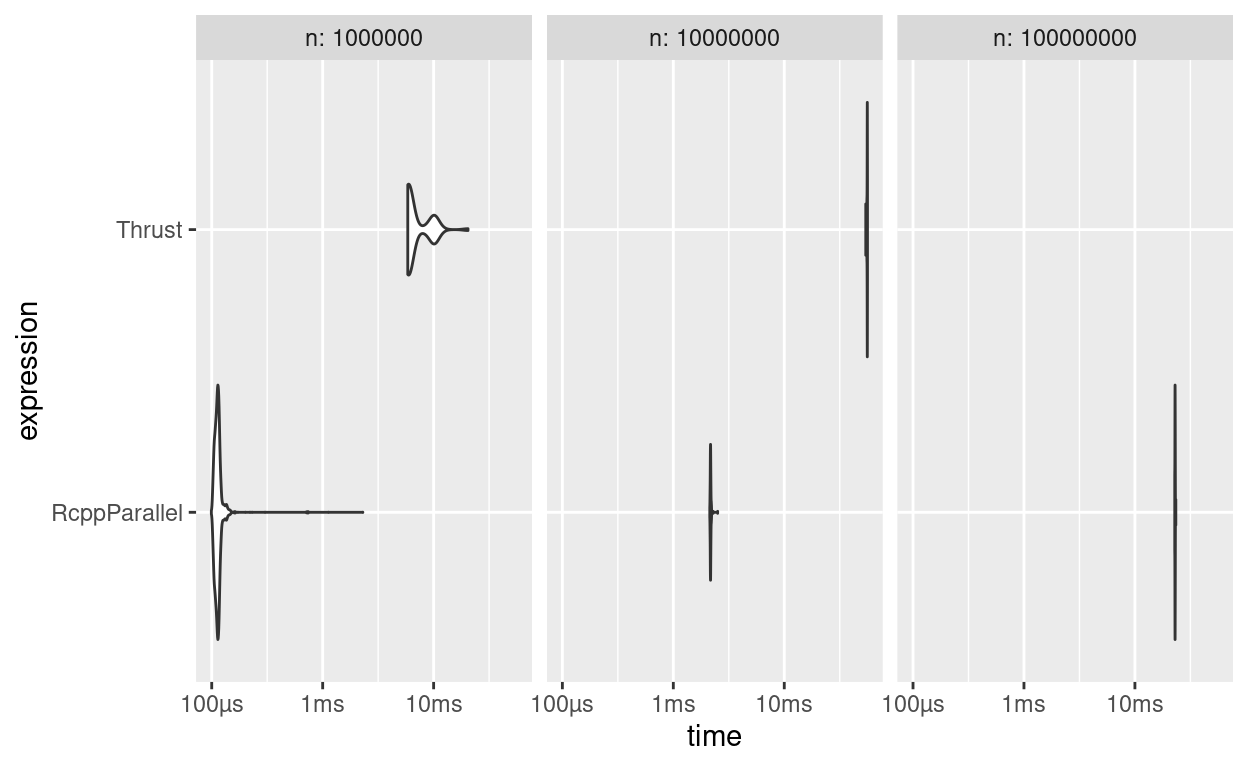
Figure 2: Benchmarks de Soma dos Quadrados: RcppParallel vs CUDA
Nesse caso específico, Thrust é 20-30x mais lento que {RcppParallel}, mas em outros contextos um código altamente paralelizável ao ser executado na GPU com CUDA pode ser que o cenário se inverta.
Ambiente
R version 4.0.3 (2020-10-10)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.10
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] cpp11_0.2.4 RcppParallel_5.0.2 Matrix_1.3-2
[4] dplyr_1.0.2 gt_0.2.2 Rcpp_1.0.5
loaded via a namespace (and not attached):
[1] here_1.0.1 lubridate_1.7.9.2
[3] lattice_0.20-41 tidyr_1.1.2
[5] ps_1.5.0 png_0.1-7
[7] assertthat_0.2.1 rprojroot_2.0.2
[9] digest_0.6.27 utf8_1.1.4
[11] R6_2.5.0 backports_1.2.1
[13] evaluate_0.14 httr_1.4.2
[15] ggplot2_3.3.3 highr_0.8
[17] pillar_1.4.7 rlang_0.4.10
[19] curl_4.3 rstudioapi_0.13
[21] callr_3.5.1 checkmate_2.0.0
[23] rmarkdown_2.6 desc_1.2.0
[25] stringr_1.4.0 RcppEigen_0.3.3.9.1
[27] igraph_1.2.6 munsell_0.5.0
[29] compiler_4.0.3 xfun_0.20
[31] pkgconfig_2.0.3 htmltools_0.5.0
[33] downlit_0.2.1 tidyselect_1.1.0
[35] tibble_3.0.4 bookdown_0.21
[37] emo_0.0.0.9000 fansi_0.4.1
[39] crayon_1.3.4 brio_1.1.0
[41] commonmark_1.7 crandep_0.1.1
[43] BH_1.72.0-3 grid_4.0.3
[45] jsonlite_1.7.2 gtable_0.3.0
[47] lifecycle_0.2.0 magrittr_2.0.1
[49] scales_1.1.1 bench_1.1.1
[51] cli_2.2.0 stringi_1.5.3
[53] profmem_0.6.0 farver_2.0.3
[55] RcppArmadillo_0.10.1.2.2 decor_1.0.0
[57] xml2_1.3.2 ellipsis_0.3.1
[59] generics_0.1.0 vctrs_0.3.6
[61] distill_1.1 cranlogs_2.1.1
[63] tools_4.0.3 glue_1.4.2
[65] purrr_0.3.4 jpeg_0.1-8.1
[67] processx_3.4.5 parallel_4.0.3
[69] yaml_2.2.1 colorspace_2.0-0
[71] rvest_0.3.6 knitr_1.30
[73] sass_0.2.0