Este tutorial apresenta os diferentes tipos de efeitos e seus tamanhos. Munido do tamanho do efeito, pesquisadores podem calcular o tamanho mínimo da amostra para que um teste estatístico possa detectar um efeito do tamanho desejado.
Tamanho de Efeito
Tamanho de efeito é definido como “um número que mede a força da relação entre duas variáveis em uma população estatística ou uma estimativa baseada em amostra dessa quantidade. Pode referir-se ao valor de uma estatística calculada a partir de uma amostra, ao valor de um parâmetro de uma população estatística hipotética ou à equação que operacionaliza como as estatísticas ou parâmetros levam ao valor do tamanho do efeito” (Kelley & Preacher, 2012). Exemplos de tamanho de efeito incluem a correlação entre duas variáveis, o coeficiente de uma variável em uma regressão e a diferença média entre grupos distintos.
Os tamanhos de efeito complementam o teste de hipótese estatística e desempenham um papel importante nas análises de poder de um teste estatístico e planejamento do tamanho da amostra.
Os tamanhos de efeito podem ser medidos em termos relativos ou absolutos. Em tamanhos de efeito relativos, dois grupos são comparados diretamente um com o outro, como em razão de probabilidades (odds ratio – OR) e riscos relativos. Para tamanhos de efeito absolutos, um valor absoluto maior sempre indica um efeito mais forte. Muitos tipos de medidas podem ser expressos como absolutos ou relativos e podem ser usados em conjunto porque transmitem informações diferentes. Se atentem ao contexto e quando usar medidas absolutas versus relativas1.
Efeitos pequenos, médios e grandes
A principal referência em tamanhos de efeito é Cohen (1988) que distingue tamanhos de efeito em pequeno, médio e grande; mas note que é necessário cautela: “Os termos ‘pequeno,’ ‘médio’ e ‘grande’ são relativos, não apenas uns aos outros, mas à área da ciência do qual pertencem ou, ainda mais particularmente, ao conteúdo específico e ao método de pesquisa empregado em qualquer investigação…” (Cohen, 1988).
Os tamanho de efeito para as diferentes métricas estatística dos testes de hipótese são definidos em Cohen (1988), mas mesmo assim eles podem variar conforme área da ciência e contexto, portanto o pesquisador deve sempre justificar (preferencialmente com argumentos baseado em evidências) caso escolha usar as métricas padrões ou caso precise alterá-las.
Neste tutorial cobriremos três principais tipos de efeito: \(d\) de Cohen, \(r\) de Pearson e \(f^2\) de Cohen. Esses tipos de efeitos são os usados em testes \(t\), ANOVA, correlação e regressão linear.
\(d\) de Cohen
O \(d\)2 de Cohen (Cohen, 1988) é a diferença entre a média de dois grupos padronizada por desvios padrões:
\[d = \frac{\mu_1 - \mu_2}{\sigma}\]
onde \(\mu_1\) é a média de um grupo, \(\mu_2\) média do outro grupo e \(\sigma\) o desvio padrão com base em ambos os grupos.
\(d\) de Cohen é usado em testes de diferença de média como o teste \(t\) e teste de Tukey. Os tamanhos de efeito para \(d\) de Cohen (Cohen, 1988) são:
- Pequeno: \(d = 0.2\)
- Médio: \(d = 0.5\)
- Grande: \(d = 0.8\)
Veja na figura 1 uma demonstração dos tamanhos de efeito de \(d\) de Cohen. Note que as medidas comparadas entre os grupos segue uma distribuição Normal (assim como o teste \(t\) de Student – paramétrico).
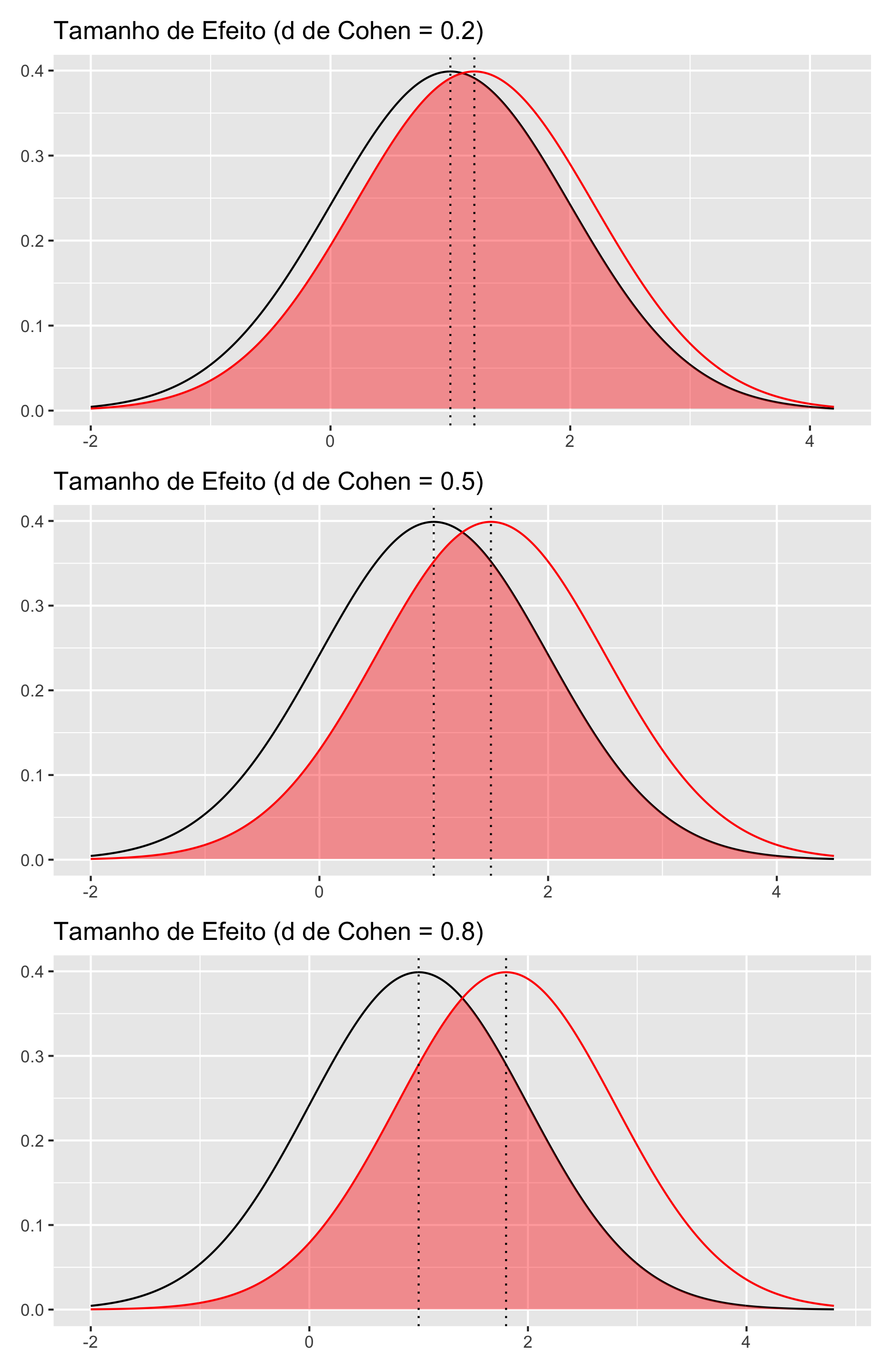
Figure 1: \(d\) de Cohen
\(r\) de Pearson
Já cruzamos com o \(r\) de Pearson(Pearson, 1895) no tutorial de correlação. Os tamanhos de efeito para \(r\) de Pearson são (Cohen, 1988):
- Pequeno: \(r = 0.1\)
- Médio: \(r = 0.3\)
- Grande: \(r = 0.5\)
Veja na figura 2 uma demonstração dos tamanhos de efeito de \(r\) de Pearson.
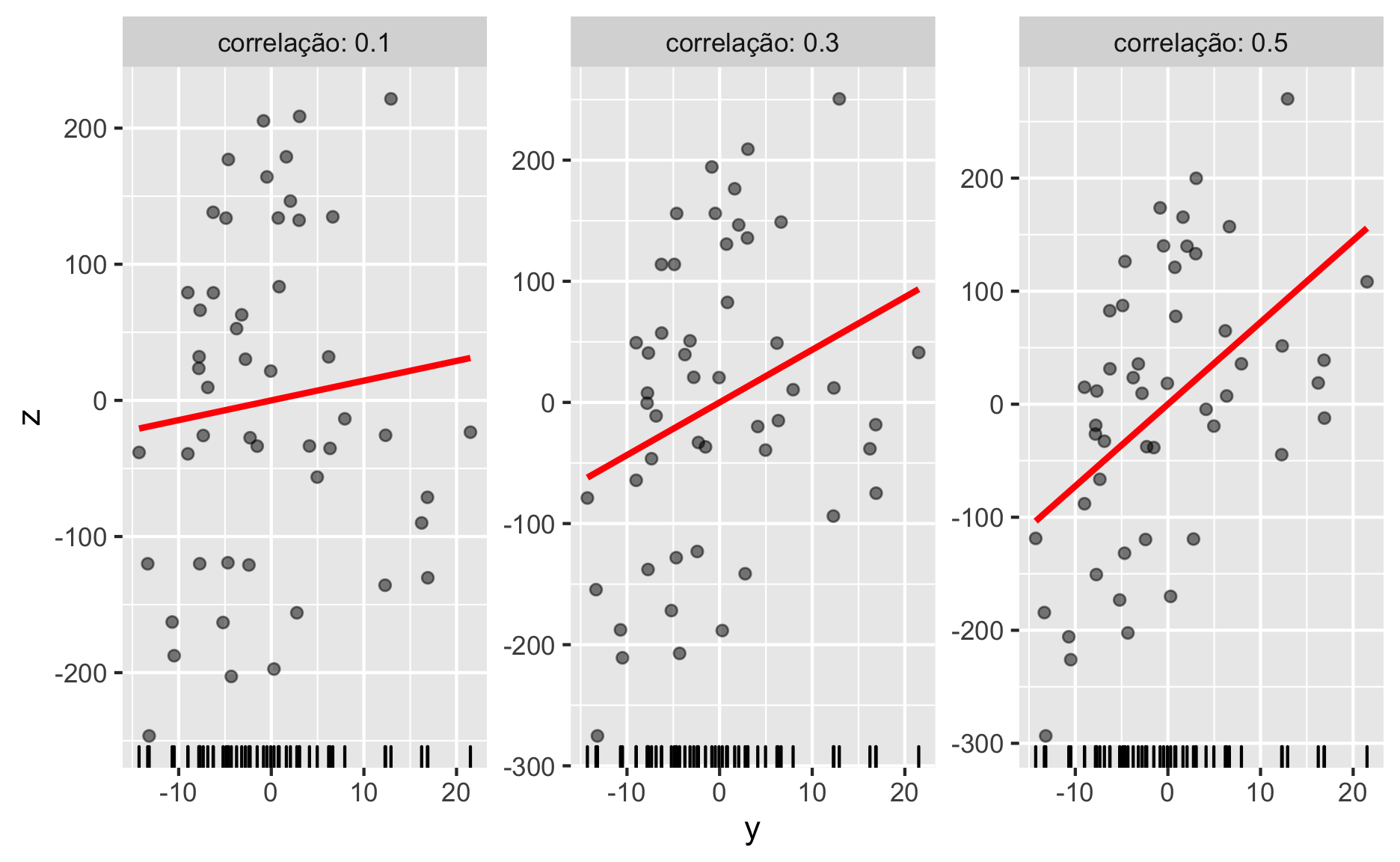
Figure 2: \(r\) de Pearson
\(f^2\) de Cohen
O \(f^2\) de Cohen é usado em contextos de testes estatísticos que usam a distribuição \(F\) de Fisher. Em ANOVAs e regressão linear, o \(f^2\) é a proporção da variabilidade na variável dependente prevista pelas variável independentes e indica o poder preditivo de um modelo estatístico. Em especial, para regressões lineares, o \(f^2\) pode ser usado como indicador de poder preditivo de um modelo completo \(R^2\) ou como indicador de poder preditivo (e poder de influência) de uma variável independente sobre uma dependente (aqui o \(f^2\) equivale ao coeficiente padronizado em desvios padrões).
Os tamanhos de efeito para \(f^2\) de Cohen (Cohen, 1988) são:
- ANOVA:
- Pequeno: \(f^2 = 0.1\)
- Médio: \(f^2 = 0.25\)
- Grande: \(f^2 = 0.4\)
- Regressão Linear:
- Pequeno: \(f^2 = 0.02\)
- Médio: \(f^2 = 0.15\)
- Grande: \(f^2 = 0.35\)
Tamanho de Amostra
O tamanho de amostra é influenciado diretamente pelo erro tipo I e erro tipo II. No tutorial de \(p\)-valores definimos dois tipos erros:
- Erro tipo I, também chamado de “falso positivo”, é a chance de rejeitarmos a hipótese nula quando ela é verdadeira. Esse erro é o alpha \(\alpha\) que é usado como limiar de significância do \(p\)-valor.
- Erro tipo II, também chamado de “falso negativo”, é a chance de não rejeitarmos a hipótese nula quando ela é falsa. Esse erro é identificado como a letra grega beta \(\beta\). Além disso, o poder de um teste estatístico é mensurado como \(1 - \beta\). O poder de um teste estatístico aumenta proporcionalmente ao tamanho amostral. Quanto maior a amostra, maior o poder do teste.

Esses dois tipos de erros foram cunhados por Jerzy Neyman, fundador do paradigma NHST3, que defendia a ideia de que é melhor absolver um culpado (erro tipo II – falso negativo) do que culpar um inocente (erro tipo I – falso positivo):
“É mais sério condenar um homem inocente ou absolver um culpado? Isso dependerá das consequências do erro. A punição é morte ou multa? Qual é o risco de criminosos libertados para a sociedade ? Quais são os pontos de vista éticos atuais sobre punição? Do ponto de vista da teoria matemática, tudo o que podemos fazer é mostrar como o risco de erros pode ser controlado e minimizado. O uso dessas ferramentas estatísticas em qualquer caso específico para determinar como o equilíbrio deve ser alcançado , deve ser deixado para o investigador.”4 (Neyman & Pearson, 1933)
Portanto, caro leitor, é você! Você deve pensar cuidadosamente em como o equilíbrio dessas taxas de erro deve ser atingido. Você não deve confiar em nenhum padrão porque cada situação exige que você considere quais seriam as taxas de erro ideais.
Com isso esclarecido, desmonstraremos como calcular o tamanho de amostra no R.
Calculando Tamanho de Amostra no R
Para calcular um tamanho de amostra no R usaremos a biblioteca {pwr} (Champely, 2020). As funções disponíveis são:
pwr.t.test()– Teste \(t\) para Amostras Independentes e para duas Amostras Pareadaspwr.r.test– Correlação usando o \(r\) de Pearsonpwr.anova.test– ANOVA Unidirecionalpwr.f2.test– Regressão Linear
A lógica do {pwr} é a seguinte. Cada uma dessas função possui argumentos para:
- Tamanho de Efeito –
d,rouf2 - Tamanho de Amostra –
n - Probabilidade do erro tipo I – falso positivo – \(\alpha\) –
sig.levelpadrão0.05 - Poder Estatístico – 1 menos a probabilidade do erro tipo II – falso negativo – \(1 - \beta\) –
power
Como esses quatro conceitos são interdependentes (para o cálculo de um é necessário saber o valor dos outros três), você deve especificar três dessas quatro métricas para obter o resultado da métrica desejada.
Exemplo 1 - Teste \(t\)
Caso queira calcular o tamanho de amostra necessário para um teste \(t\) detectar um efeito médio, \(d = 0.5\), com taxa de falso positivo (\(\alpha\)) de 5%, e poder estatístico (\(1 - \beta\)) de 80%:
library(pwr)
pwr.t.test(d = 0.5, sig.level = 0.05, power = 0.8)
Two-sample t test power calculation
n = 63.76561
d = 0.5
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* groupSão necessário dois grupos com 64 observações em cada grupo. Um total de amostra de 128 observações.
Exemplo 2 - Regressão Linear
Vamos para um segundo exemplo com regressão linear. Aqui o uso da função pwr.f2.test() é um pouco mais complicado porque, além do tamanho de efeito f2, sig.level, n e power, temos que especificar os graus de liberdade do numerador u e graus de liberdade do denominador v.
Os graus de liberdade do numerador, u, é o número de coeficientes que você terá em seu modelo (menos a constante): \(u = \text{coeficientes} - 1\). Os graus de liberdade do denominador, v, é o número de graus de liberdade do erro do modelo. Você pode calcular os graus de liberdade do denominador subtraindo o número de observações de amostra do número total de coeficientes exceto a constante menos 1. Então \(v = n - u - 1\).
Suponha que você queira saber o tamanho de amostra necessário para uma regressão linear com cinco variáveis independentes detectar efeitos grandes, \(f^2 = 0.35\), com taxa de falso positivo (\(\alpha\)) de 1%, e poder estatístico (\(1 - \beta\)) de 95%. Aqui temos u = 5, pois são seis coeficientes (contando com a constante) menos a constante (\(6-1=5\)).
pwr.f2.test(f2 = 0.35, u = 5, sig.level = 0.01, power = 0.95)
Multiple regression power calculation
u = 5
v = 75.3845
f2 = 0.35
sig.level = 0.01
power = 0.95Veja que o resultado não nos informa um tamanho amostral, mas sim os graus de liberdade do denominador: v. Lembre-se que \(v = n - u - 1\), então \(n = v + u + 1\). Portanto nosso tamanho amostral é 81. Isto quer dizer que para identificar efeitos grandes, de no mínimo \(f^2 = 0.35\), tanto para \(R^2\) quanto para influências das variáveis independentes (em coeficientes padronizados por desvios padrões), com \(\alpha\) em 1% e poder estatístico de 95%, é necessário no mínimo uma amostra com 81 observações.
Ambiente
R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods
[7] base
other attached packages:
[1] pwr_1.3-0 MASS_7.3-53 likert_1.3.5
[4] xtable_1.8-4 naniar_0.6.0.9000 purrr_0.3.4
[7] gtsummary_1.3.6 gt_0.2.2 lm.beta_1.5-1
[10] lmtest_0.9-38 zoo_1.8-8 ggfortify_0.4.11
[13] sjPlot_2.8.7 broom_0.7.4 palmerpenguins_0.1.0
[16] magrittr_2.0.1 mnormt_2.0.2 cowplot_1.1.1
[19] tidyr_1.1.2 DescTools_0.99.40 skimr_2.1.2
[22] ggpubr_0.4.0 car_3.0-10 carData_3.0-4
[25] patchwork_1.1.1 dplyr_1.0.4 ggplot2_3.3.3
[28] DiagrammeR_1.0.6.1 readxl_1.3.1
loaded via a namespace (and not attached):
[1] backports_1.2.1 plyr_1.8.6 repr_1.1.3
[4] splines_4.0.3 usethis_2.0.1 digest_0.6.27
[7] htmltools_0.5.1.1 magick_2.6.0 fansi_0.4.2
[10] checkmate_2.0.0 openxlsx_4.2.3 modelr_0.1.8
[13] colorspace_2.0-0 haven_2.3.1 xfun_0.21
[16] crayon_1.4.1 jsonlite_1.7.2 Exact_2.1
[19] lme4_1.1-26 survival_3.2-7 glue_1.4.2
[22] gtable_0.3.0 emmeans_1.5.4 sjstats_0.18.1
[25] sjmisc_2.8.6 abind_1.4-5 scales_1.1.1
[28] mvtnorm_1.1-1 DBI_1.1.1 rstatix_0.6.0
[31] ggeffects_1.0.1 Rcpp_1.0.6 performance_0.7.0
[34] tmvnsim_1.0-2 reticulate_1.18 foreign_0.8-80
[37] htmlwidgets_1.5.3 RColorBrewer_1.1-2 ellipsis_0.3.1
[40] pkgconfig_2.0.3 farver_2.0.3 sass_0.3.1
[43] utf8_1.1.4 reshape2_1.4.4 tidyselect_1.1.0
[46] labeling_0.4.2 rlang_0.4.10 effectsize_0.4.3
[49] munsell_0.5.0 cellranger_1.1.0 tools_4.0.3
[52] visNetwork_2.0.9 cli_2.3.0 generics_0.1.0
[55] sjlabelled_1.1.7 evaluate_0.14 stringr_1.4.0
[58] yaml_2.2.1 fs_1.5.0 knitr_1.31
[61] zip_2.1.1 visdat_0.5.3 rootSolve_1.8.2.1
[64] nlme_3.1-149 xml2_1.3.2 compiler_4.0.3
[67] rstudioapi_0.13 curl_4.3 e1071_1.7-4
[70] ggsignif_0.6.0 tibble_3.0.6 statmod_1.4.35
[73] broom.helpers_1.1.0 stringi_1.5.3 highr_0.8
[76] parameters_0.11.0 forcats_0.5.1 lattice_0.20-41
[79] Matrix_1.2-18 psych_2.0.12 commonmark_1.7
[82] nloptr_1.2.2.2 ggsci_2.9 vctrs_0.3.6
[85] norm_1.0-9.5 pillar_1.4.7 lifecycle_0.2.0
[88] estimability_1.3 data.table_1.13.6 insight_0.12.0
[91] lmom_2.8 R6_2.5.0 bookdown_0.21
[94] gridExtra_2.3 rio_0.5.16 gld_2.6.2
[97] distill_1.2 boot_1.3-25 assertthat_0.2.1
[100] rprojroot_2.0.2 withr_2.4.1 parallel_4.0.3
[103] mgcv_1.8-33 bayestestR_0.8.2 expm_0.999-6
[106] hms_1.0.0 labelled_2.7.0 grid_4.0.3
[109] class_7.3-17 minqa_1.2.4 rmarkdown_2.6
[112] downlit_0.2.1 lubridate_1.7.9.2 base64enc_0.1-3 autor 1 ficou indignado quanto um estudo falou que um grupo possuía 50% mais risco de acidente cardiovascular que outro grupo ao transformar o risco absoluto dos dois grupos, mensurados em 1.005 e 1.0075, em risco relativo. Aqui a diferença de risco absoluto é 0.25%, mas quando convertido para risco relativo se torna 50%!↩︎
\(d\) de diferença↩︎
Null Hypothesis Significance Testing – NHST (tradução: teste de significância de hipótese nula)↩︎
do original em inglês: “Is it more serious to convict an innocent man or to acquit a guilty? That will depend upon the consequences of the error. Is the punishment death or fine? What is the danger to the community of released criminals? What are the current ethical views on punishment? From the point of view of mathematical theory, all that we can do is to show how the risk of errors may be controlled and minimized. The use of these statistical tools in any given case in determining just how the balance should be struck, must be left to the investigator.”↩︎